%matplotlib inline
import numpy as np
from scipy.stats import sem
import matplotlib.pyplot as plt
from rl_glue import RLGlue
import agent
import cliffworld_env
from tqdm import tqdm
import pickle
plt.rcParams.update({'font.size': 15})
plt.rcParams.update({'figure.figsize': [10,5]})
Section 1: Q-Learning
In this section you will implement and test a Q-Learning agent with $\epsilon$-greedy action selection (Section 6.5 in the textbook).
Implementation
Your job is to implement the updates in the methods agent_step and agent_end. We provide detailed comments in each method describing what your code should do.
# Q-Learning agent here
class QLearningAgent(agent.BaseAgent):
def agent_init(self, agent_init_info):
"""Setup for the agent called when the experiment first starts.
Args:
agent_init_info (dict), the parameters used to initialize the agent. The dictionary contains:
{
num_states (int): The number of states,
num_actions (int): The number of actions,
epsilon (float): The epsilon parameter for exploration,
step_size (float): The step-size,
discount (float): The discount factor,
}
"""
# Store the parameters provided in agent_init_info.
self.num_actions = agent_init_info["num_actions"]
self.num_states = agent_init_info["num_states"]
self.epsilon = agent_init_info["epsilon"]
self.step_size = agent_init_info["step_size"]
self.discount = agent_init_info["discount"]
self.rand_generator = np.random.RandomState(agent_info["seed"])
# Create an array for action-value estimates and initialize it to zero.
self.q = np.zeros((self.num_states, self.num_actions)) # The array of action-value estimates.
def agent_start(self, state):
"""The first method called when the episode starts, called after
the environment starts.
Args:
state (int): the state from the
environment's evn_start function.
Returns:
action (int): the first action the agent takes.
"""
# Choose action using epsilon greedy.
current_q = self.q[state,:]
if self.rand_generator.rand() < self.epsilon:
action = self.rand_generator.randint(self.num_actions)
else:
action = self.argmax(current_q)
self.prev_state = state
self.prev_action = action
return action
def agent_step(self, reward, state):
"""A step taken by the agent.
Args:
reward (float): the reward received for taking the last action taken
state (int): the state from the
environment's step based on where the agent ended up after the
last step.
Returns:
action (int): the action the agent is taking.
"""
# Choose action using epsilon greedy.
if self.rand_generator.rand() < self.epsilon:
action = self.rand_generator.randint(self.num_actions)
else:
action = self.argmax(self.q[state, :])
# Perform an update (1 line)
### START CODE HERE ###
self.q[self.prev_state, self.prev_action] += self.step_size * (reward + self.discount * np.max(self.q[state, :]) \
- self.q[self.prev_state, self.prev_action])
### END CODE HERE ###
self.prev_state = state
self.prev_action = action
return action
def agent_end(self, reward):
"""Run when the agent terminates.
Args:
reward (float): the reward the agent received for entering the
terminal state.
"""
# Perform the last update in the episode (1 line)
### START CODE HERE ###
self.q[self.prev_state, self.prev_action] += self.step_size * (reward- self.q[self.prev_state, self.prev_action])
### END CODE HERE ###
def argmax(self, q_values):
"""argmax with random tie-breaking
Args:
q_values (Numpy array): the array of action-values
Returns:
action (int): an action with the highest value
"""
top = float("-inf")
ties = []
for i in range(len(q_values)):
if q_values[i] > top:
top = q_values[i]
ties = []
if q_values[i] == top:
ties.append(i)
return self.rand_generator.choice(ties)
Test
Run the cells below to test the implemented methods. The output of each cell should match the expected output.
Note that passing this test does not guarantee correct behavior on the Cliff World.
# Do not modify this cell!
## Test Code for agent_start() ##
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = QLearningAgent()
current_agent.agent_init(agent_info)
action = current_agent.agent_start(0)
print("Action Value Estimates: \n", current_agent.q)
print("Action:", action)
Action Value Estimates:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Action: 1
Expected Output:
Action Value Estimates:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Action: 1
# Do not modify this cell!
## Test Code for agent_step() ##
actions = []
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = QLearningAgent()
current_agent.agent_init(agent_info)
actions.append(current_agent.agent_start(0))
actions.append(current_agent.agent_step(2, 1))
actions.append(current_agent.agent_step(0, 0))
print("Action Value Estimates: \n", current_agent.q)
print("Actions:", actions)
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.02]
[0. 0. 0. 0. ]]
Actions: [1, 3, 1]
Expected Output:
Action Value Estimates:
[[ 0. 0.2 0. 0. ]
[ 0. 0. 0. 0.02]
[ 0. 0. 0. 0. ]]
Actions: [1, 3, 1]
# Do not modify this cell!
## Test Code for agent_end() ##
actions = []
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = QLearningAgent()
current_agent.agent_init(agent_info)
actions.append(current_agent.agent_start(0))
actions.append(current_agent.agent_step(2, 1))
current_agent.agent_end(1)
print("Action Value Estimates: \n", current_agent.q)
print("Actions:", actions)
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.1]
[0. 0. 0. 0. ]]
Actions: [1, 3]
Expected Output:
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.1]
[0. 0. 0. 0. ]]
Actions: [1, 3]
Section 2: Expected Sarsa
In this section you will implement an Expected Sarsa agent with $\epsilon$-greedy action selection (Section 6.6 in the textbook).
Implementation
Your job is to implement the updates in the methods agent_step and agent_end. We provide detailed comments in each method describing what your code should do.
class ExpectedSarsaAgent(agent.BaseAgent):
def agent_init(self, agent_init_info):
"""Setup for the agent called when the experiment first starts.
Args:
agent_init_info (dict), the parameters used to initialize the agent. The dictionary contains:
{
num_states (int): The number of states,
num_actions (int): The number of actions,
epsilon (float): The epsilon parameter for exploration,
step_size (float): The step-size,
discount (float): The discount factor,
}
"""
# Store the parameters provided in agent_init_info.
self.num_actions = agent_init_info["num_actions"]
self.num_states = agent_init_info["num_states"]
self.epsilon = agent_init_info["epsilon"]
self.step_size = agent_init_info["step_size"]
self.discount = agent_init_info["discount"]
self.rand_generator = np.random.RandomState(agent_info["seed"])
# Create an array for action-value estimates and initialize it to zero.
self.q = np.zeros((self.num_states, self.num_actions)) # The array of action-value estimates.
def agent_start(self, state):
"""The first method called when the episode starts, called after
the environment starts.
Args:
state (int): the state from the
environment's evn_start function.
Returns:
action (int): the first action the agent takes.
"""
# Choose action using epsilon greedy.
current_q = self.q[state, :]
if self.rand_generator.rand() < self.epsilon:
action = self.rand_generator.randint(self.num_actions)
else:
action = self.argmax(current_q)
self.prev_state = state
self.prev_action = action
return action
def agent_step(self, reward, state):
"""A step taken by the agent.
Args:
reward (float): the reward received for taking the last action taken
state (int): the state from the
environment's step based on where the agent ended up after the
last step.
Returns:
action (int): the action the agent is taking.
"""
# Choose action using epsilon greedy.
if self.rand_generator.rand() < self.epsilon:
action = self.rand_generator.randint(self.num_actions)
else:
action = self.argmax(self.q[state,:])
# Perform an update (~5 lines)
### START CODE HERE ###
expected_q = 0
q_max = np.max(self.q[state,:])
pi = np.ones(self.num_actions) * self.epsilon / self.num_actions \
+ (self.q[state,:] == q_max) * (1 - self.epsilon) / np.sum(self.q[state,:] == q_max)
expected_q = np.sum(self.q[state,:] * pi)
self.q[self.prev_state, self.prev_action] += self.step_size * (reward + self.discount * expected_q \
- self.q[self.prev_state, self.prev_action])
### END CODE HERE ###
self.prev_state = state
self.prev_action = action
return action
def agent_end(self, reward):
"""Run when the agent terminates.
Args:
reward (float): the reward the agent received for entering the
terminal state.
"""
# Perform the last update in the episode (1 line)
### START CODE HERE ###
self.q[self.prev_state, self.prev_action] += self.step_size * (reward- self.q[self.prev_state, self.prev_action])
### END CODE HERE ###
def argmax(self, q_values):
"""argmax with random tie-breaking
Args:
q_values (Numpy array): the array of action-values
Returns:
action (int): an action with the highest value
"""
top = float("-inf")
ties = []
for i in range(len(q_values)):
if q_values[i] > top:
top = q_values[i]
ties = []
if q_values[i] == top:
ties.append(i)
return self.rand_generator.choice(ties)
Test
Run the cells below to test the implemented methods. The output of each cell should match the expected output.
Note that passing this test does not guarantee correct behavior on the Cliff World.
# Do not modify this cell!
## Test Code for agent_start() ##
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = ExpectedSarsaAgent()
current_agent.agent_init(agent_info)
action = current_agent.agent_start(0)
print("Action Value Estimates: \n", current_agent.q)
print("Action:", action)
Action Value Estimates:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Action: 1
Expected Output:
Action Value Estimates:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Action: 1
# Do not modify this cell!
## Test Code for agent_step() ##
actions = []
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = ExpectedSarsaAgent()
current_agent.agent_init(agent_info)
actions.append(current_agent.agent_start(0))
actions.append(current_agent.agent_step(2, 1))
actions.append(current_agent.agent_step(0, 0))
print("Action Value Estimates: \n", current_agent.q)
print("Actions:", actions)
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.0185]
[0. 0. 0. 0. ]]
Actions: [1, 3, 1]
Expected Output:
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.0185]
[0. 0. 0. 0. ]]
Actions: [1, 3, 1]
# Do not modify this cell!
## Test Code for agent_end() ##
actions = []
agent_info = {"num_actions": 4, "num_states": 3, "epsilon": 0.1, "step_size": 0.1, "discount": 1.0, "seed": 0}
current_agent = ExpectedSarsaAgent()
current_agent.agent_init(agent_info)
actions.append(current_agent.agent_start(0))
actions.append(current_agent.agent_step(2, 1))
current_agent.agent_end(1)
print("Action Value Estimates: \n", current_agent.q)
print("Actions:", actions)
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.1]
[0. 0. 0. 0. ]]
Actions: [1, 3]
Expected Output:
Action Value Estimates:
[[0. 0.2 0. 0. ]
[0. 0. 0. 0.1]
[0. 0. 0. 0. ]]
Actions: [1, 3]
Section 3: Solving the Cliff World
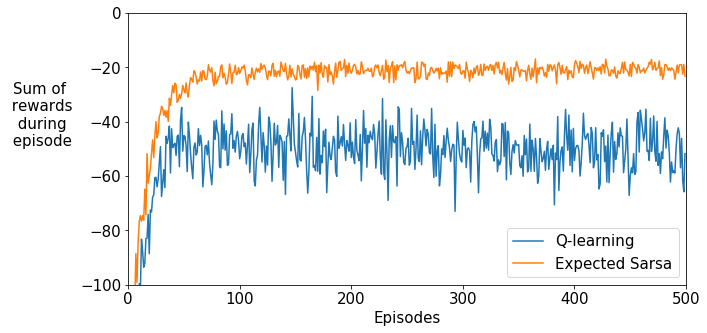
We described the Cliff World environment in the video “Expected Sarsa in the Cliff World” in Lesson 3. This is an undiscounted episodic task and thus we set $\gamma$=1. The agent starts in the bottom left corner of the gridworld below and takes actions that move it in the four directions. Actions that would move the agent off of the cliff incur a reward of -100 and send the agent back to the start state. The reward for all other transitions is -1. An episode terminates when the agent reaches the bottom right corner.

Using the experiment program in the cell below we now compare the agents on the Cliff World environment and plot the sum of rewards during each episode for the two agents.
The result of this cell will be graded. If you make any changes to your algorithms, you have to run this cell again before submitting the assignment.
# Do not modify this cell!
agents = {
"Q-learning": QLearningAgent,
"Expected Sarsa": ExpectedSarsaAgent
}
env = cliffworld_env.Environment
all_reward_sums = {} # Contains sum of rewards during episode
all_state_visits = {} # Contains state visit counts during the last 10 episodes
agent_info = {"num_actions": 4, "num_states": 48, "epsilon": 0.1, "step_size": 0.5, "discount": 1.0}
env_info = {}
num_runs = 100 # The number of runs
num_episodes = 500 # The number of episodes in each run
for algorithm in ["Q-learning", "Expected Sarsa"]:
all_reward_sums[algorithm] = []
all_state_visits[algorithm] = []
for run in tqdm(range(num_runs)):
agent_info["seed"] = run
rl_glue = RLGlue(env, agents[algorithm])
rl_glue.rl_init(agent_info, env_info)
reward_sums = []
state_visits = np.zeros(48)
# last_episode_total_reward = 0
for episode in range(num_episodes):
if episode < num_episodes - 10:
# Runs an episode
rl_glue.rl_episode(0)
else:
# Runs an episode while keeping track of visited states
state, action = rl_glue.rl_start()
state_visits[state] += 1
is_terminal = False
while not is_terminal:
reward, state, action, is_terminal = rl_glue.rl_step()
state_visits[state] += 1
reward_sums.append(rl_glue.rl_return())
# last_episode_total_reward = rl_glue.rl_return()
all_reward_sums[algorithm].append(reward_sums)
all_state_visits[algorithm].append(state_visits)
# save results
import os
import shutil
os.makedirs('results', exist_ok=True)
np.save('results/q_learning.npy', all_reward_sums['Q-learning'])
np.save('results/expected_sarsa.npy', all_reward_sums['Expected Sarsa'])
shutil.make_archive('results', 'zip', '.', 'results')
for algorithm in ["Q-learning", "Expected Sarsa"]:
plt.plot(np.mean(all_reward_sums[algorithm], axis=0), label=algorithm)
plt.xlabel("Episodes")
plt.ylabel("Sum of\n rewards\n during\n episode",rotation=0, labelpad=40)
plt.xlim(0,500)
plt.ylim(-100,0)
plt.legend()
plt.show()
100%|██████████| 100/100 [00:22<00:00, 4.37it/s]
100%|██████████| 100/100 [00:52<00:00, 1.89it/s]
To see why these two agents behave differently, let’s inspect the states they visit most. Run the cell below to generate plots showing the number of timesteps that the agents spent in each state over the last 10 episodes.
# Do not modify this cell!
for algorithm, position in [("Q-learning", 211), ("Expected Sarsa", 212)]:
plt.subplot(position)
average_state_visits = np.array(all_state_visits[algorithm]).mean(axis=0)
grid_state_visits = average_state_visits.reshape((4,12))
grid_state_visits[0,1:-1] = np.nan
plt.pcolormesh(grid_state_visits, edgecolors='gray', linewidth=2)
plt.title(algorithm)
plt.axis('off')
cm = plt.get_cmap()
cm.set_bad('gray')
plt.subplots_adjust(bottom=0.0, right=0.7, top=1.0)
cax = plt.axes([0.85, 0.0, 0.075, 1.])
cbar = plt.colorbar(cax=cax)
cbar.ax.set_ylabel("Visits during\n the last 10\n episodes", rotation=0, labelpad=70)
plt.show()
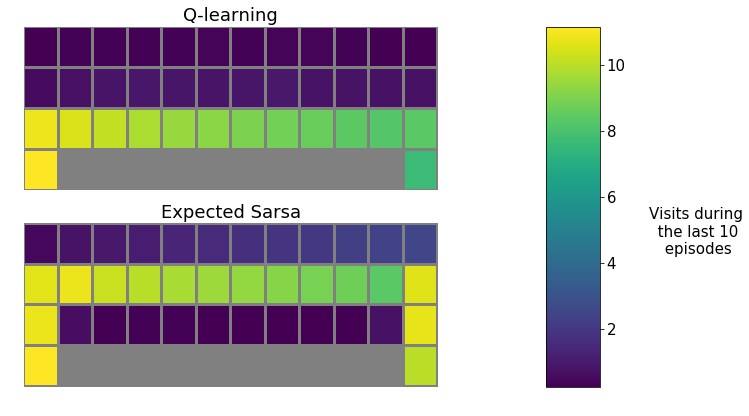
The Q-learning agent learns the optimal policy, one that moves along the cliff and reaches the goal in as few steps as possible. However, since the agent does not follow the optimal policy and uses $\epsilon$-greedy exploration, it occasionally falls off the cliff. The Expected Sarsa agent takes exploration into account and follows a safer path. Note this is different from the book. The book shows Sarsa learns the even safer path
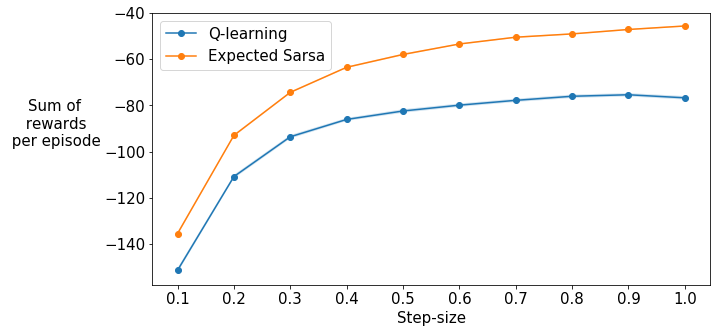
Previously we used a fixed step-size of 0.5 for the agents. What happens with other step-sizes? Does this difference in performance persist?
In the next experiment we will try 10 different step-sizes from 0.1 to 1.0 and compare the sum of rewards per episode averaged over the first 100 episodes (similar to the interim performance curves in Figure 6.3 of the textbook). Shaded regions show standard errors.
This cell takes around 10 minutes to run. The result of this cell will be graded. If you make any changes to your algorithms, you have to run this cell again before submitting the assignment.
# Do not modify this cell!
agents = {
"Q-learning": QLearningAgent,
"Expected Sarsa": ExpectedSarsaAgent
}
env = cliffworld_env.Environment
all_reward_sums = {}
step_sizes = np.linspace(0.1,1.0,10)
agent_info = {"num_actions": 4, "num_states": 48, "epsilon": 0.1, "discount": 1.0}
env_info = {}
num_runs = 100
num_episodes = 100
all_reward_sums = {}
for algorithm in ["Q-learning", "Expected Sarsa"]:
for step_size in step_sizes:
all_reward_sums[(algorithm, step_size)] = []
agent_info["step_size"] = step_size
for run in tqdm(range(num_runs)):
agent_info["seed"] = run
rl_glue = RLGlue(env, agents[algorithm])
rl_glue.rl_init(agent_info, env_info)
return_sum = 0
for episode in range(num_episodes):
rl_glue.rl_episode(0)
return_sum += rl_glue.rl_return()
all_reward_sums[(algorithm, step_size)].append(return_sum/num_episodes)
for algorithm in ["Q-learning", "Expected Sarsa"]:
algorithm_means = np.array([np.mean(all_reward_sums[(algorithm, step_size)]) for step_size in step_sizes])
algorithm_stds = np.array([sem(all_reward_sums[(algorithm, step_size)]) for step_size in step_sizes])
plt.plot(step_sizes, algorithm_means, marker='o', linestyle='solid', label=algorithm)
plt.fill_between(step_sizes, algorithm_means + algorithm_stds, algorithm_means - algorithm_stds, alpha=0.2)
plt.legend()
plt.xlabel("Step-size")
plt.ylabel("Sum of\n rewards\n per episode",rotation=0, labelpad=50)
plt.xticks(step_sizes)
plt.show()
100%|██████████| 100/100 [00:20<00:00, 4.96it/s]
100%|██████████| 100/100 [00:14<00:00, 6.92it/s]
100%|██████████| 100/100 [00:10<00:00, 9.45it/s]
100%|██████████| 100/100 [00:09<00:00, 10.74it/s]
100%|██████████| 100/100 [00:08<00:00, 12.01it/s]
100%|██████████| 100/100 [00:08<00:00, 12.36it/s]
100%|██████████| 100/100 [00:07<00:00, 12.82it/s]
100%|██████████| 100/100 [00:07<00:00, 13.48it/s]
100%|██████████| 100/100 [00:07<00:00, 13.55it/s]
100%|██████████| 100/100 [00:07<00:00, 14.06it/s]
100%|██████████| 100/100 [00:43<00:00, 2.27it/s]
100%|██████████| 100/100 [00:31<00:00, 3.17it/s]
100%|██████████| 100/100 [00:25<00:00, 3.93it/s]
100%|██████████| 100/100 [00:21<00:00, 4.55it/s]
100%|██████████| 100/100 [00:19<00:00, 5.12it/s]
100%|██████████| 100/100 [00:18<00:00, 5.48it/s]
100%|██████████| 100/100 [00:17<00:00, 5.86it/s]
100%|██████████| 100/100 [00:16<00:00, 5.96it/s]
100%|██████████| 100/100 [00:15<00:00, 6.30it/s]
100%|██████████| 100/100 [00:15<00:00, 6.38it/s]
Wrapping up
Expected Sarsa shows an advantage over Q-learning in this problem across a wide range of step-sizes.
Congratulations! Now you have:
- implemented Q-Learning with $\epsilon$-greedy action selection
- implemented Expected Sarsa with $\epsilon$-greedy action selection
- investigated the behavior of these two algorithms on Cliff World
To submit your solution, you will need to submit the results.zip file generated by the experiments. Here are the steps:
- Go to the
filemenu at the top of the screen - Select
open - Click the selection square next to
results.zip - Select
Downloadfrom the top menu - Upload that file to the grader in the next part of this module